Variable-length fuzzy hashes with Nilsimsa for did you mean correction
Or, why fuzzy hashing isn't helpful for improving a search engine. Welcome to another blog post about one of my special interests: search engines - specifically the implementation thereof :D
I've blogged about search engines before, in which I looked at taking my existing search engine implementation to the next level by switching to a SQLite-based key-value datastore backing and stress-testing it with ~5M words. Still not satisfied, I'm now turning my attention to query correction. Have you ever seen something like this when you make a typo when you do a search?
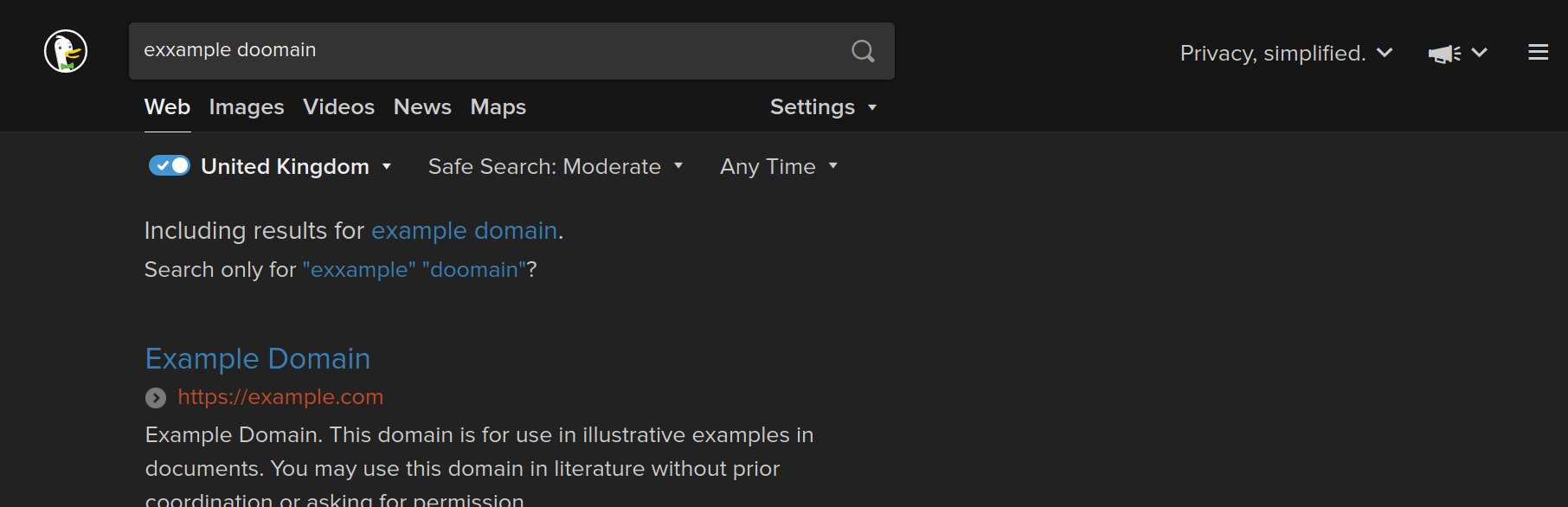
Surprisingly, this is actually quite challenging to achieve. The problem is that given a word with a typo in it, while it's easy to determine if a word contains a typo, it's hard to determine what the correct version of the word is. Consider a wordlist like this:
apple
orange
pear
grape
pineapple
If the user entered something like pinneapple, then it's obvious to us that the correct spelling would be pineapple - but in order to determine this algorithmically you need an algorithm capable of determining how close 2 different words are to 1 another.
The most popular algorithm for this is called leveshtein. Given 2 words a and b, it calculates the number of edits to turn a into b. For example, the edit distance between pinneapple and pineapple is 1.
This is useful, but it still doesn't help us very much. With this, we'd have to calculate the leveshtein distance between the typo and all the words in the list. This could easily run into millions of words for large wikis, so this is obviously completely impractical.
To this end, we need a better idea. In this post, I'm going to talk about my first attempt at solving this problem. I feel it's important to document failures as well as successes, so this is part 1 of a 2 part series.
The first order of business is to track down a Nilsimsa implementation in PHP - since it doesn't come built-in, and it's pretty complicated to implement. Thankfully, this isn't too hard - I found this one on GitHub.
Nilsimsa is a fuzzy hashing algorithm. This means that if you hash 2 similar words, then you'll get 2 similar hashes:
| Word |
Hash |
pinneapple |
020c2312000800920004880000200002618200017c1021108200421018000404 |
pineapple |
0204239242000042000428018000213364820000d02421100200400018080200256 |
If you look closely, you'll notice that the hashes are quite similar. My thinking is that if we vary the hash size, then words that are similar will have identical hashes, allowing the search space to be cut down significantly. The existing Nilsimsa implementation I've found doesn't support that though, so we'll need to alter it.
This didn't turn out to be too much of a problem. By removing some magic numbers and adding a class member variable, it seems to work like a charm:
(Can't view the above? Try this direct link.)
I removed the comparison functions since I'm not using them (yet?), and also added a static convenience method for generating hashes. If I end up using this for large quantities of hashes, I may come back to it make it resettable, to avoid having to create a new object for every hash.
With this, we can get the variable-length hashes we wanted:
256 0a200240020004a180810950040a00d033828480cd16043246180e54444060a5
128 3ba286c0cf1604b3c6990f54444a60f5
64 02880ed0c40204b1
32 060a04f0
16 06d2
8 06
The number there is the number of bits in the hash, and the hex value is the hash itself. The algorithm defaults to 256-bit hashes. Next, we need to determine which sized hash is best. The easiest way to do this is to take a list of typos, hash the typo and the correction, and count the number of hashes that are identical.
Thankfully, there's a great dataset just for this purpose. Since it's formatted in CSV, we can download it and extract the typos and corrections in 1 go like this:
curl https://raw.githubusercontent.com/src-d/datasets/master/Typos/typos.csv | cut -d',' -f2-3 >typos.csv
There's also a much larger dataset too, but that one is formatted as JSON objects and would require a bunch of processing to get it into a format that would be useful here - and since this is just a relatively quick test to get a feel for how our idea works, I don't think it's too crucial that we use the larger dataset just yet.
With the dataset downloaded, we can run our test. First, we need to read the file in line-by line for every hash length we want to test:
<?php
$handle = fopen("typos.csv", "r");
$sizes = [ 256, 128, 64, 32, 16, 8 ];
foreach($sizes as $size) {
fseek($handle, 0); // Jump back to the beginning
fgets($handle); // Skip the first line since it's the header
while(($line = fgets($handle)) !== false) {
// Do something with the next line here
}
}
PHP has an inbuilt function fgets() which gets the next line of input from a file handle, which is convenient. Next, we need to actually do the hashes and compare them:
<?php
// .....
$parts = explode(",", trim($line), 2);
if(strlen($parts[1]) < 3) {
$skipped++;
continue;
}
$hash_a = Nilsimsa::hash($parts[0], $size);
$hash_b = Nilsimsa::hash($parts[1], $size);
$count++;
if($hash_a == $hash_b) {
$count_same++;
$same[] = $parts;
}
else {
$not_same[] = $parts;
}
echo("$count_same / $count ($skipped skipped)\r");
// .....
Finally, a bit of extra logic around the edges and we're ready for our test:
<?php
$handle = fopen("typos.csv", "r");
$line_count = lines_count($handle);
echo("$line_count lines total\n");
$sizes = [ 256, 128, 64, 32, 16, 8 ];
foreach($sizes as $size) {
fseek($handle, 0);fgets($handle); // Skipt he first line since it's the header
$count = 0; $count_same = 0; $skipped = 0;
$same = []; $not_same = [];
while(($line = fgets($handle)) !== false) {
$parts = explode(",", trim($line), 2);
if(strlen($parts[1]) < 3) {
$skipped++;
continue;
}
$hash_a = Nilsimsa::hash($parts[0], $size);
$hash_b = Nilsimsa::hash($parts[1], $size);
$count++;
if($hash_a == $hash_b) {
$count_same++;
$same[] = $parts;
}
else $not_same[] = $parts;
echo("$count_same / $count ($skipped skipped)\r");
}
file_put_contents("$size-same.csv", implode("\n", array_map(function ($el) {
return implode(",", $el);
}, $same)));
file_put_contents("$size-not-same.csv", implode("\n", array_map(function ($el) {
return implode(",", $el);
}, $not_same)));
echo(str_pad($size, 10)."→ $count_same / $count (".round(($count_same/$count)*100, 2)."%), $skipped skipped\n");
}
I'm writing the pairs that are the same and different to different files here for a visual inspection. I'm also skipping words that are less than 3 characters long, and that lines_count() function there is just a quick helper function for counting the number of lines in a file for the progress indicator (if you write a \r without a \n to the terminal, it'll reset to the beginning of the current line):
<?php
function lines_count($handle) : int {
fseek($handle, 0);
$count = 0;
while(fgets($handle) !== false) $count++;
return $count;
}
Unfortunately, the results of running the test aren't too promising. Even with the shortest hash the algorithm will generate without getting upset, only ~23% of typos generate the same hash as their correction:
7375 lines total
256 → 7 / 7322 (0.1%), 52 skipped
128 → 9 / 7322 (0.12%), 52 skipped
64 → 13 / 7322 (0.18%), 52 skipped
32 → 64 / 7322 (0.87%), 52 skipped
16 → 347 / 7322 (4.74%), 52 skipped
8 → 1689 / 7322 (23.07%), 52 skipped
Furthermore, digging deeper with an 8-bit you start to get large numbers of words that have the same hash, which isn't ideal at all.
A potential solution here would be to use hamming distance (basically counting the number of bits that are different in a string of binary) to determine which hashes are similar to each other like leveshtein distance does, but that still doesn't help us as we then still have a problem that's almost identical to where we started.
In the second part of this mini-series, I'm going to talk about how I ultimately solved this problem. While the algorithm I ultimately used (a BK-Tree, more on them next time) is certainly not the most efficient out there (it's O(log n) if I understand it correctly), it's very simple to implement and is much less complicated than Symspell, which seems to be the most efficient algorithm that exists at the moment.
Additionally, I have been able to optimise said algorithm to return results for a 172K wordlist in ~110ms, which is fine for my purposes.
Found this interesting? Got another algorithm I should check out? Got confused somewhere along the way? Comment below!

 Mailing List
Mailing List
 Articles Atom Feed
Articles Atom Feed
 Comments Atom Feed
Comments Atom Feed
 Twitter
Twitter
 Reddit
Reddit
 Facebook
Facebook











 (Above: Some microSD cards. Thankfully none of these are fake, but you never know.....)
(Above: Some microSD cards. Thankfully none of these are fake, but you never know.....) 